Shadow Paging in DBMS? Example, Advantages, Disadvantages
Shadow Paging in DBMS? Example, Advantages, Disadvantages: The process of recovering data in a database management system is known as Shadow Paging. It is a recovery technique where the transactions are performed in the main memory. After completion of transactions, they get updated in the database. However, it didn’t show up in the database if failures happen during transaction execution.
Also See: Stylish Font
Also See: What is RAID in DBMS: 7 Levels with Advantages and Methods
There are tons of queries on the internet regarding shadow paging that our team will try to uncover using this post. We suggest checking the entire post to ensure you have all the required information.
Shadow Paging in DBMS? Example, Advantages, Disadvantages
Shadow paging is a recovery method for retrieving data in DBMS. The main use of this technique is maintaining the consistency in data if failure happens in any case. The technique is also known with the name of Cut of Place Updating. There is no need to log in to a single user environment while performing this technique. However, the system needs a log for concurrency control during the multiuser environment.
It offers durability and atomicity to the system in the entire process. This concept utilizes quite a few disks for completing the operation. It is known to give power to manipulating pages in a database that is a very important step to perform.
Also See: File Organization in DBMS: Types with Advantages and Importance
What Kinds of Functions does Shadow Paging Perform in Different Environments?
It needs to be understood that the shadow paging causes a different effect on different environments. Although most programmers don’t take this thing seriously, it is strongly suggested to understand this prospect. Allow us to explain this prospect in detail below:
- Single User Environment
If we talk about the single-user environment, the recovery scheme never asks for the log. The entire operation can be easily completed without the use of a log in any manner.
- Multi-User Environment
Things are entirely different when we talk about performing shadow paging in a multiuser environment. There will be strongly a requirement for a log as it involves a concurrency control procedure.
Example of Shadow Paging
As we all know, it is considered a perfect alternative for log-based recovery. Let’s understand the shadow paging using the figure. Here, the motive is to maintain two-page tables in the entire lifecycle named Shadow Page Table and Current Page Table.
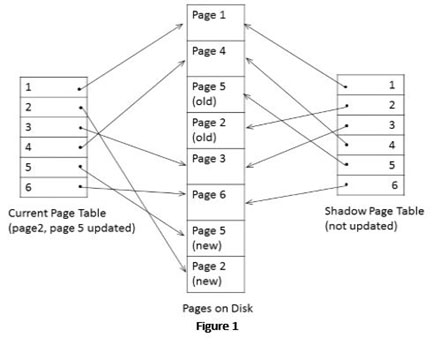
In the case of shadow paging, the database is created using a certain number of particular size disk pages to perform the recovery process. The directory has N number of entries where the sixth entry points to the sixth database on the disk. The current directory goes towards the current database pages once a transaction starts and gets copied to the directory named shadow page.
Also See: Aggregation in DBMS: Types, Example, Techniques and Importance
The current directory is used during the operation, whereas a non-volatile disk is used to save the shadow directory. Therefore, there is no modification performed on the shadow directory when the execution of the transaction is performed. Instead, a copy of modified data is developed during the execution of the write operation without performing over-writing.
A new page written on a disk block isn’t completely unused. The modification work is performed on the current directory, and it gets pointed to the new disk block. On the other hand, no modification work is performed on the shadow directory, and it continuously points towards the unmodified disk block.
There are two versions maintained for updated pages. The shadow directory references the older version, whereas the current directory is used for pointing to new versions. If recovery needs to be performed from failure, the modified data is released, followed by throwing away the current directory.
The status of data can be accessed through the shadow directory prior to the execution of transaction. After that, the shadow directory is reinstated to recover the state. In this way, the entire process of shadow paging is performed.
Also See: Metadata in DBMS, Types and Importance
Advantages of Shadow Paging in DBMS?
Shadow paging is an over log-based method that offers a great set of advantages we have mentioned in detail below:
- There is overhead removed in log record output with the help of shadow paging. It makes sure that the recovery process is performed in a much better way from the crash.
- The shadow paging asks for a very less number of disks for performing the entire operation.
- The operations like Undo and Redo don’t need to be performed during shadow paging.
- It is an inexpensive and faster method to perform recovery after a crash.
Disadvantages of shadow paging in DBMS?
The post won’t get completed without mentioning the disadvantages of shadow paging that are mentioned below:
- It becomes tough to maintain pages that are closer to the disk due to location changes.
- There is a chance of data fragmentation while performing shadow paging.
- The system needs multiple blocks for performing a single transaction which reduces the execution speed.
- Extending the algorithm becomes difficult for letting transactions operate concurrently.
Also See: Examples of Popular Database Management Systems (DBMS)
Shadow paging different from log-based recovery?
Log-based recovery is a very important used structure to record database modifications. Many people inquire how they are different from the shadow paging. Have a look at the major differences between the two below:
- The log record is made using different fields like data item identifier, transaction identifier, new value, and old value. On the other hand, shadow paging is made from a certain number of fixed-size disk pages.
- The search process in the log-based recovery is quite long, while things become faster in shadow paging thanks to the elimination of overhead of log record output.
- There is a need for only one block to complete a single transaction in log-based recovery, but the commit of one transaction asks for multiple blocks in shadow paging.
- The locality property of pages can be lost in shadow paging, while it never happens in log-based recovery.
Also See: Generalization in DBMS with Example
Shadow Paging is one of the most critical operations in the database management system. There is a variety of steps performed during the execution of the transaction. Do you have a few queries regarding the shadow paging? Feel free to write about it in the comment section!
Leave a Reply