File Organization in DBMS: Types with Advantages and Importance
File Organization in DBMS: Types with Advantages and Importance: The File Organization can be defined as the logical relationships between different records in the file. It is mainly related to finding and accessing any particular record. If we talk simply, file organization means storing files in a particular sequence for logical control.
Also See: What Is A Database?
However, file organization is a broad term that needs to be adequately explored before reaching any conclusion. Therefore, this post will talk about broadly about the file organization in DBMS.
File Organization in DBMS: Types with Advantages and Importance
There are various methods for organizing files with each offering advantages and disadvantages. It is up to the programmer to select the ideal method matching their needs. Have a look at the few major types of file organizations in detail below:
-
Sequential File Organization
The sequential file organization is an extremely simple method of storing the data components sequentially in the binary format. It supports different data operations, like insert, deletes, update, and retrieve the data. The identification gets possible due to the presence of unique data attributes that also assist in placing the data elements in the required sequence.
In DBMS, it is known as the logical sequencing for storing the data components in the computer memory.
For example, there are records stored in a sequential manner on tracks of a magnetic drum. However, every record has an index assigned to it for assessing them in a direct manner.
Also See: Characteristics of Database Approach
This type of file organization is further divided into two sub-sections we have mentioned below:
- Sorted File Method
In the sorted file method, the data components are arranged in ascending or descending order according to the primary keys. There is new data component inserted at the file’s end position when we use this type of file organization in DBMS.
- Pile File Method
The sequential file organization where the data elements are stored in the order they are inserted is known as the pile file method. It is one of the most commonly found file organization techniques in DBMS.
-
Heap File Organization
According to programmers, this type is the simplest and easiest form of file organization. The Heap File Organization works with data blocks. Here, the records are inserted into the data blocks at the end of the file without keeping any sorting or ordering in mind. There is a new record stored in other blocks if a data block doesn’t have any further memory.
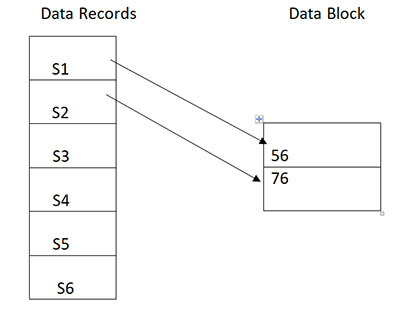
Advantages of Heap File Organization
- If we compare it with sequential records, the fetching and retrieving record work is performed at a much higher speed.
- It perfectly suits the situation where a high quantity of data is required to load into the database.
-
Clustered File Organization
The file organization where two or more similar records are stored in a single file is known as clustered file organization. Here, there are two or more tables located in the similar data block. It is strongly helpful in minimizing the expenses of searching and retrieving different records in various files because they are combined in a single cluster. The main part of this file organization is the cluster key that joins the table.
Also See: Traditional File Processing System in DBMS
Have a look at the below tables to understand clustered file organization better:
Staff
| Staff-ID | Name | City | Dep_ID |
| 1 | Liza | London | 10 |
| 2 | Daniel | Manchester | 11 |
| 3 | Tim | Sydney | 12 |
| 4 | Amy | London | 13 |
| 5 | Jazz | Mumbai | 14 |
| 6 | Sani | Tokyo | 15 |
| 7 | Ali | Madras | 16 |
Department
| DEP_ID | DEP_Name |
| 10 | R & D |
| 11 | Quality |
| 12 | Production |
| DEP_ID | Staff_ID | Staff_Name | City | DEP_Name |
| 11 | 2 | Daniel | Manchester | Quality |
| 12 | 3 | Tim | Sydney | Production |
Here DEP_ID is the cluster key using which table can be joined. Using this type of file organization, the programmers can directly update, insert or add any record.
There are two types of clustered file organization mentioned below:
- Hash Clusters
In hash clusters, the storing of records are made according to the hash key value that are generated by programmers.
- Indexed Clusters
Here, the records are managed on the basis of a cluster key that is mainly used for combining a certain table.
Also See: Structure of DBMS: Users and Interfaces with Diagram
-
B+ Tree File Organization
B+ Tree File Organization involves a highly advanced level of indexed sequential access techniques for storing files in a database. It has a tree-like structure where key indexing is used for sorting the records. Here, traversing becomes very easier and quicker for the programmers.
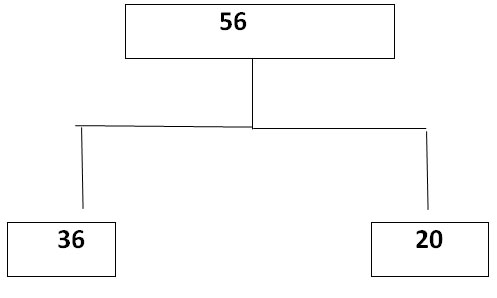
Look at the above-mentioned example to better understand this type of file organization
- The root node of the tree is 56
- Further, there is a node on the left side and right sides with the value of 36 and 20, respectively.
- There will be further values in the leaf node.
This way the leaf nodes get balanced, and searching becomes easier for programmers.
Advantages of B+ Tree File Organization
- This concept makes searching super convenient and easier because the records are kept in the leaf nodes and sorted sequentially.
- Performing commands like insert/update/delete don’t cause any effect on the performance thanks to a balanced tree structure.
Why is file organization important in DBMS?
There is a huge sort of data stored in the database in the form of files. Every file has lots of records stored in binary format. File organization is used for defining these records adequately. Have a look at the main motives of file organization in detail below:
- It consists of an adequate selection of records to ensure they can be selected at a quicker rate.
- File organization allows the programmers to add transactions like update, delete or insert conveniently and quickly.
- Makes sure that duplicate records don’t enter the system due to commands like insert, delete or update.
- It helps to store the records efficiently for reducing the storage cost to the minimum level.
Also See: Complete Guide: Denormalization in Database (DBMS)
We hope that our readers fully understand what file organization in DBMS is. Do you still have any queries in mind? Don’t forget to tell us in the comment section!
Leave a Reply